the and to of a was I in
coben_breaker 3.592 1.175 2.163 1.376 2.519 1.502 1.445 1.176
coben_dropshot 3.588 1.179 2.122 1.269 2.375 1.567 1.497 1.040
coben_fadeaway 3.931 1.445 2.200 1.213 2.306 1.323 1.330 1.198
coben_falsemove 3.625 1.613 2.134 1.237 2.401 1.375 1.346 1.109
coben_goneforgood 3.834 1.817 2.153 1.176 1.962 1.733 3.814 1.131
coben_nosecondchance 4.098 1.589 2.271 1.206 1.992 1.758 3.855 1.151
coben_tellnoone 4.102 1.790 2.031 1.246 2.176 1.418 3.499 1.162
galbraith_cuckoos 4.523 2.267 2.494 2.179 2.141 1.656 1.127 1.380
lewis_battle 5.051 3.405 2.138 2.138 1.960 1.511 0.902 1.284
lewis_caspian 4.865 3.592 2.153 2.144 2.168 1.353 1.115 1.212
lewis_chair 4.973 3.221 1.997 2.103 2.354 1.405 1.073 1.214
lewis_horse 4.885 3.487 2.306 2.224 2.322 1.403 1.195 1.298
lewis_lion 5.141 3.699 2.295 2.185 2.100 1.346 0.813 1.162
lewis_nephew 4.482 2.856 2.070 2.231 2.311 1.571 1.179 1.355
lewis_voyage 5.222 3.279 2.261 2.114 2.244 1.583 1.048 1.153
rowling_casual 4.749 2.639 2.625 2.108 1.763 1.646 0.561 1.443
rowling_chamber 4.415 2.344 2.352 1.877 2.001 1.481 0.882 1.168
rowling_goblet 4.483 2.426 2.486 2.022 1.791 1.423 0.849 1.117
rowling_hallows 4.696 2.473 2.244 1.870 1.449 1.126 0.525 0.995Text Analysis Is Easy
Unless It Is Not:
Reliability Issues
in Measuring Textual Similarities
Maciej Eder
Polish Academy of Sciences | University of Tartu
05/03/2025
https://tinyurl.com/dhnb2025
introduction
Blaise Pascal: two infinities
- imaginary journey to the far end (?) of the Universe
- imaginary journey into our own body
- one finds no limits there
scientific revolution

revolution in the humanities
- new tools: computer & the internet
- new resources: research infrastructures, several datasets
- new methods: data mining, machine learning
- new disciplines: Digital Humanities
infrastructures in DH
Computational Literary Studies Infrastructure (CLS INFRA) is a four-year partnership to build a shared resource of high-quality data, tools and knowledge to aid new approaches to studying literature in the digital age.
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101004984.
CLS INFRA project
- text collections (corpora)
- quality
- metadata
- conversion
- methodology
- tools (NLP, datavis, …)
- methodological considerations
- bibliographic survey
- network of scholars
- training schools
- short-term research stays
ELTeC corpus

DraCor programmable corpora

survey of methods

text analysis
text analysis: two approaches
- focusing on the content
- what my corpus is about?
- how to “read” through a large library
- approaches: topic modeling, keywords analysis
- focusing on stylistic similarities
- why my texts form groups?
- how to detect different stylistics “signals”
- approaches: multivariate text classification methods
theoretical foundations
- “Computation into criticism” (John Burrows)
- “Algorithmic criticism” (Steve Ramsay)
- “Distant reading” (Franco Moretti)
- “Macroanalysis” (Matt Jockers)
- “Riddle of literary quality” (Karina van Dalen-Oskam)
why text analysis?
- authorship attribution
- forensic linguistics
- register analysis
- genre recognition
- gender differences
- translatorial signal
- early vs. mature style
- style evolution
- detecting dementia
- …
What makes them different?
text A:
I have just returned from a visit to my landlord - the solitary neighbour that I shall be troubled with. This is certainly a beautiful country! In all England, I do not believe that I could have fixed on a situation so completely removed from the stir of society. A perfect misanthropist's heaven: and Mr. Heathcliff and I are such a suitable pair to divide the desolation between us. A capital fellow!text B:
OF MANS First Disobedience, and the Fruit
Of that Forbidden Tree, whose mortal tast
Brought Death into the World, and all our woe,
With loss of Eden, till one greater Man
Restore us, and regain the blissful Seat,
Sing Heav'nly Muse, that on the secret top
Of Oreb, or of Sinai, didst inspire
That Shepherd, who first taught the chosen Seed,
In the Beginning how the Heav'ns and Earth
Rose out of Chaos: or if Sion Hill
Delight thee more, and Siloa's Brook that flow'd
Fast by the Oracle of God; I thence
Invoke thy aid to my adventrous Song,how to compare a set of texts?
- extracting valuable (i.e. countable) language features from texts
- frequencies of words 👈
- frequencies of syllables
- versification patterns
- distribution of topics
- …
- comparing these features by means of multivariate analysis
- distance-based methods 👈
- neural networks
- …
from words to features
‘It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.’
(J. Austen, Pride and Prejudice)
“the” = 3.52%
“to” = 3.39%
“of” = 2.94%
“a” = 1.59%
“in” = 1.53%
“was” = 1.50%
. . .
from features to similarities
what we hope to get

software (feat. ‘stylo’)
Text analysis software
- Mallet
- Gensim
- sklearn
- Excel
- Statistica
- Orange Data Mining
- JGAAP
- stylo 👈
- …
stylo: a package for text analysis
- an R package
- written in R and runs in R
- simple
- fast
- offers a few extensions
- runs in command-line mode 😱
- . . . but requires only three lines of code
- no programming skills needed!
how to run stylo
graphical user interface (GUI)
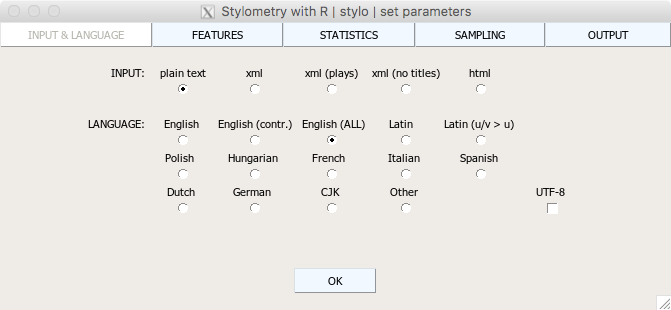
set your parameters
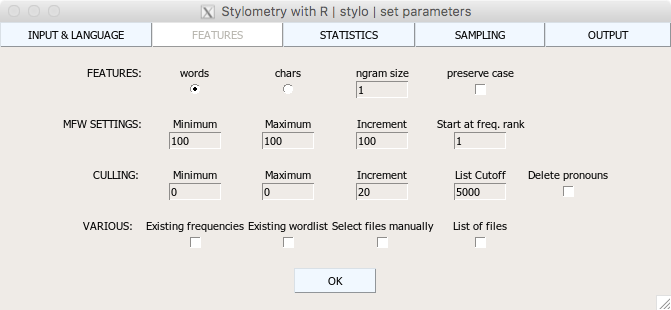
hierarchical cluster analysis

multidimensional scaling

66 English Victorian novels
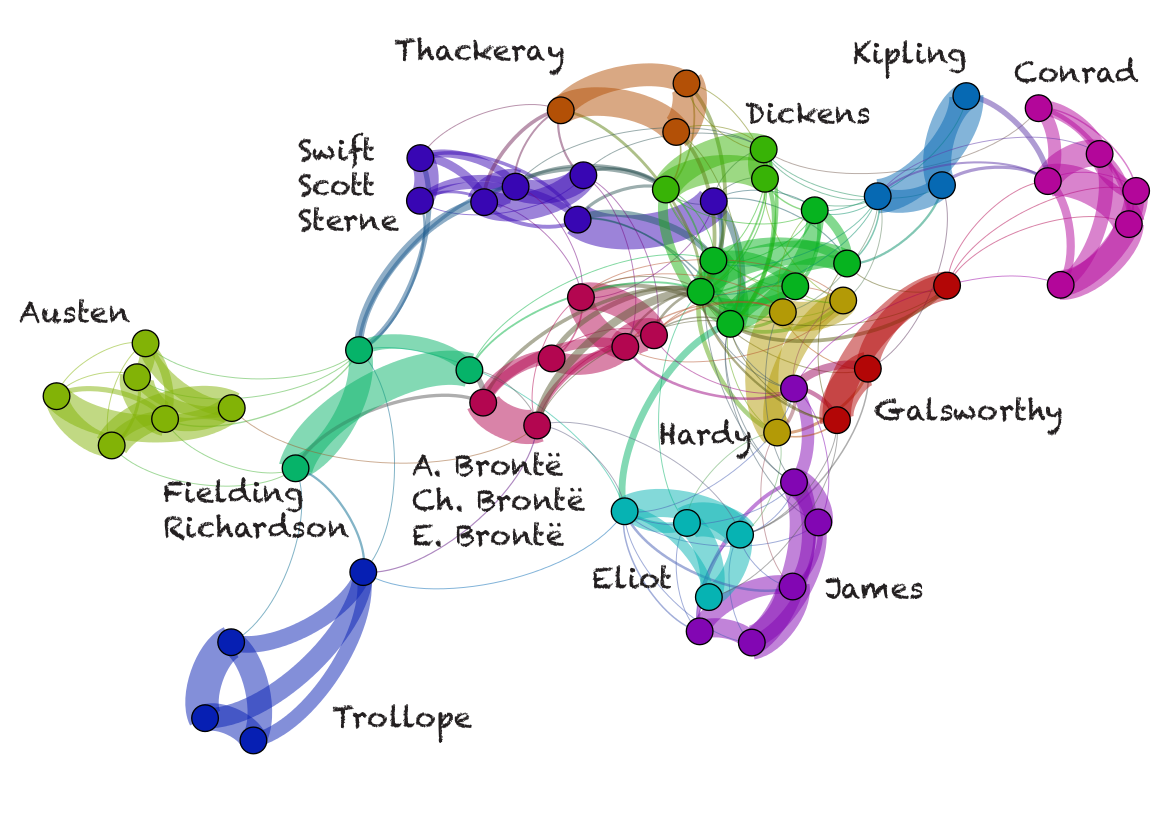
stylo’s extensions
words distributed unevenly

Zeta method to extract keywords

women are from Venus . . .
Female words: feelings glance effort paused feeling surprise noticed pause consciousness dared enjoyment tone listen exclaimed features seated continually anxiety solitude inward apparently painful entrance respectable relief closed watching feel bent peculiar rain suddenly cheerful clear trees aspect watched plan slight doubtles reached smile brow vague quiet mere movement gathered suffering entered listened observed warm exertion minutes change . . .
Male words: story although lord bosom honour honest duke parliament city score enemy coach coat inn thousand breast bill dozen lordship guilty court ain legs bottle captain fight pen battle sum nevertheless reader virtue order innocent condition infinite castle widow england accident readers laws fellows hundred service king stories persons ladyship fly street dearest honours member fortune government wig drank papers wretch described honourable pocket
sequential analysis

Roman de la Rose
- 13th-century French allegorical poem
- mixed authorship:
- Guillaume de Lorris (ca. 1230)
- Jean de Meun (ca. 1275)
- The takeover point known (after the line 4,058)
Roman de la Rose sequentially

uncertainty everywhere
risk of being overly simplistic
- fast results, especially using default parameters
- tempting to apply a tool as a simple problem-solver
- tacit assumption that statistics “tells the truth”
- humanists tend to overestimate numbers, plots, and maps
- hard scientists tend to underestimate language variation
- tendency to forget about uncertainty in the dataset
word frequencies agin
‘It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.’
(J. Austen, Pride and Prejudice)
“the” = 3.52% 👈
“to” = 3.39%
“of” = 2.94%
“a” = 1.59%
“in” = 1.53%
“was” = 1.50%
. . .
what is a word frequency, really?
- frequency of “the” in Pride and Prejudice is 3.52%
- however, if we devide the text into 122 chunks of 1,000 words:
- 2.3, 4.2, 4.4, 2.9, 3.3, 2.9, 2.6, 4, 3.5, 4.5, 2.2, 3.1, 2.8, 4, 3.3, 3.9, 2.8, 4.1, 3.3, 3.6, 3.4, 5.3, 6.1, 3.8, 3.2, 3.6, 3.8, 4.3, 2.9, 3.6, 3.7, 3.9, 4.2, 3.8, 2.8, 3.2, 4.5, 3.8, 3.9, 3.6, 3.5, 3.5, 2.4, 3.5, 3, 2.7, 1.9, 3.8, 4.8, 4.9, 4.7, 3.2, 5.8, 4.6, 2.5, 3.9, 4, 2.8, 3.4, 3.4, 6, 4.2, 3.5, 2.9, 5.4, 3.5, 3.1, 3.7, 3.5, 4.8, 2.7, 3.8, 4, 2.9, 4.3, 5.8, 3.8, 5, 5.6, 3.6, 3.8, 3.7, 4.4, 4.4, 2.5, 2.6, 2,1 etc.
- max value: 6.1%
- min value: 1.9%
- what is the frequency of “the”, after all???
frequency is a distribution
slicing input text into tokens...
turning words into features, e.g. char n-grams (if applicable)...
distribution of the word ‘the’

arithmetic mean

point estimates?

point estimates are misleading
slicing input text into tokens...
turning words into features, e.g. char n-grams (if applicable)...
the distributions are unknown
- which features should be choosen
- 100 most frequent words?
- or perhaps 1,000 most frequent words?
- or maybe character 3-grams are better?
- which parameters should be preferred
- Cosine Delta distance?
- Burrows Delta distance?
- minmax distance?
- the results will always be slightly different
- . . . and the distributions are unknown
exploring different features

sampling from the features
the and to of a was I in
coben_breaker 3.592 1.175 2.163 1.376 2.519 1.502 1.445 1.176
coben_dropshot 3.588 1.179 2.122 1.269 2.375 1.567 1.497 1.040
coben_fadeaway 3.931 1.445 2.200 1.213 2.306 1.323 1.330 1.198
coben_falsemove 3.625 1.613 2.134 1.237 2.401 1.375 1.346 1.109
coben_goneforgood 3.834 1.817 2.153 1.176 1.962 1.733 3.814 1.131
coben_nosecondchance 4.098 1.589 2.271 1.206 1.992 1.758 3.855 1.151
coben_tellnoone 4.102 1.790 2.031 1.246 2.176 1.418 3.499 1.162
galbraith_cuckoos 4.523 2.267 2.494 2.179 2.141 1.656 1.127 1.380
lewis_battle 5.051 3.405 2.138 2.138 1.960 1.511 0.902 1.284
lewis_caspian 4.865 3.592 2.153 2.144 2.168 1.353 1.115 1.212
lewis_chair 4.973 3.221 1.997 2.103 2.354 1.405 1.073 1.214
lewis_horse 4.885 3.487 2.306 2.224 2.322 1.403 1.195 1.298
lewis_lion 5.141 3.699 2.295 2.185 2.100 1.346 0.813 1.162
lewis_nephew 4.482 2.856 2.070 2.231 2.311 1.571 1.179 1.355
lewis_voyage 5.222 3.279 2.261 2.114 2.244 1.583 1.048 1.153
rowling_casual 4.749 2.639 2.625 2.108 1.763 1.646 0.561 1.443
rowling_chamber 4.415 2.344 2.352 1.877 2.001 1.481 0.882 1.168
rowling_goblet 4.483 2.426 2.486 2.022 1.791 1.423 0.849 1.117
rowling_hallows 4.696 2.473 2.244 1.870 1.449 1.126 0.525 0.995General Imposters method
Testing the textual similarities of The Sound and the Fury:
No candidate set specified; testing the following classes (one at a time): Capote Faulkner Glasgow HarperLee McCullers OConnor Styron Welty Testing a given candidate against imposters...Capote 0.04Faulkner 0.9Glasgow 0HarperLee 0.2McCullers 0.01OConnor 0.02Styron 0.01Welty 0.61 Capote Faulkner Glasgow HarperLee McCullers OConnor Styron Welty
0.04 0.90 0.00 0.20 0.01 0.02 0.01 0.61 conclusions
closing remarks
- ‘stylo’ has been around for some time
- it became a de facto standard in text classification
- easy to use, but sometimes too easy
- mind that statistics does not tell The Truth
- several features that are in fact distributions
- several parameters that are in fact distributions
- suggestion: use tools with care!
thank you!
![]()